Google Phác Họa Qui Trình Máy học (Machine Learning) – Phần 1

Big Data và vai trò của Machine learning
Big Data là không phải là một thuật ngữ khoa học chính thống nhưng đang ngày một phổ biến trong thời kỳ bùng nổ dữ liệu hiện nay, nơi mà nhu cầu chia sẻ thông tin của người dùng Internet tăng trưởng một cách chóng mặt. Hãy cụ thể hóa qua một vài con số sau đây:
- Hiện có hơn 3,2 tỷ người dùng trên Internet.
- Mỗi ngày, Google phải xử lý hơn 4,4 tỷ lượt tìm kiếm, tương đương với khoảng 51.000 lượt/giây.
- Mỗi phút có hơn 300 giờ video được upload trên Youtube với khoảng 110.000 video được xem trong mỗi giây.
- Facebook có gần 1,5 tỷ người dùng đang hoạt động.
Con số này vẫn đang tăng theo từng giây. Đó là lý do tại Web Summit 2015 –’hội thảo công nghệ lớn nhất hành tinh’ được tổ chức đầu tháng 11 vừa qua tại Dublin (Ai len), Big Data đã được xem là “kỷ nguyên mới của quảng cáo”.
Nhưng làm cách nào các công ty quảng cáo có thể biến nguồn dữ liệu dồi dào này thành hành động? Đến đây vấn đề không chỉ là về Big Data, mà còn là về Fast Data – ám chỉ khả năng thấu hiểu và xử lý dữ liệu nhanh nhất có thể để cho ra các quyết định chính xác theo thời gian thực.
Yêu cầu này vượt quá khả năng của não bộ con người. Chúng ta cần một cỗ máy có khả năng hỗ trợ xử lý và biến lượng dữ liệu khổng lồ này thành các thông tin thực sự có giá trị – đó chính là Machine learning, còn gọi là qui trình “Máy học”.
Các công ty công nghệ đầu ngành hiện nay như Facebook hay Google đang tiêu tốn ngân sách không nhỏ để phát triển thế hệ Machine learning mới và ngày càng toàn diện hơn. Một tiết lộ gần đây liên quan đến việc Google đang sử dụng Machine learning để xử lý các kết quả tìm kiếm đã thu hút được sự quan tâm của cộng đồng đối với công nghệ thuộc lĩnh vực trí tuệ nhân tạo này.
Vậy cơ chế hoạt động của Machine learning là gì? Làm thế nào máy móc có thể tiến hành quá trình tự học và xử lý vấn đề như não bộ của con người?
Đây là một vấn đề kỹ thuật phức tạp và khó tiếp thu bởi những người không chuyên về phát triển hệ thống, ví dụ như các Marketer. Do đó, để đơn giản hóa, có thể xem Machine Learning như một qui trình giúp cho máy tính có được khả năng nhận thức và phản xạ cơ bản giống như con người – nghe, nhìn, hiểu được ngôn ngữ, nhận biết vật thể, giải toán, lập trình,…
Trong sự kiện Machine Learning 101 được tổ chức hôm 3/11 vừa qua, Greg Corrado, nhà khoa học nghiên cứu cấp cao kiêm đồng sáng lập nhóm Machine learning của Google, đã phác thảo sơ lược Machine learning thông qua việc mô tả cơ bản quá trình máy tính thiết lập các mô hình dự báo.
Các qui trình cơ bản của Machine learning
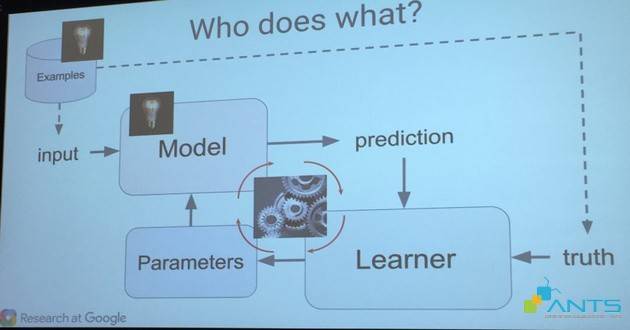
Các phần chính của một qui trình Machine learning bao gồm:
- Mô hình (Model) – là hệ thống mô phỏng các mẫu hình từ thực tế giúp đưa ra dự báo hoặc nhận dạng.
- Các thông số (Parameter) – là những tín hiệu hoặc yếu tố được cho là có khả năng gây ảnh hưởng lên kết quả mô hình, được sử dụng để đưa ra quyết định.
- Cơ chế học hỏi (Learner) – là quá trình đánh giá, đối chiếu khác biệt giữa các dự báo và kết quả thực tế, tiến hành các điều chỉnh thông số hợp lý cho đến khi mô hình đạt được mức độ chính xác đặt ra.
Giả sử trong thực tế phát sinh một nhu cầu như sau: một giảng viên muốn xác định được lượng thời gian tối đa sinh viên cần dành cho việc học để đạt được điểm số cao nhất có thể.
Nhu cầu này được cụ thể hóa thành bài toán: tạo ra một cơ chế giúp dự báo điểm số kiểm tra khi biết được thời gian dành cho việc học, qua đó cũng giúp xác định thời gian học tối ưu để đạt kết quả tốt nhất.
Dĩ nhiên một giảng viên có thể thực hiện điều tra một nhóm sinh viên, sau đó xác định một mẫu hình chung cho nhóm này và thực hiện các ước lượng một cách thủ công. Tuy nhiên trong thống kê, mẫu cần phải đủ lớn để cho độ chính xác nhất định. Bên cạnh đó, qui trình mô phỏng thực tế này đòi hỏi quá trình điều chỉnh lặp đi lặp lại không ngừng với lượng lớn dữ liệu. Điều này gây lãng phí thời gian, công sức và nhiều khi vượt quá khả năng của con người. Chính lúc này một quá trình Machine learning sẽ phát huy hiệu quả tốt nhất.
Bước 1 – Thiết lập mô hình (Model)
Để bắt đầu quá trình, giảng viên phải là người đưa ra những giả định đầu tiên vào mô hình, bao gồm:
- Các biến (x) nào tác động lên kết quả mô hình (y): Ở đây chỉ có một yếu tố gây ảnh hưởng (x) là ‘thời gian học tập’, còn đầu ra (y) chính là ‘kết quả kiểm tra’.
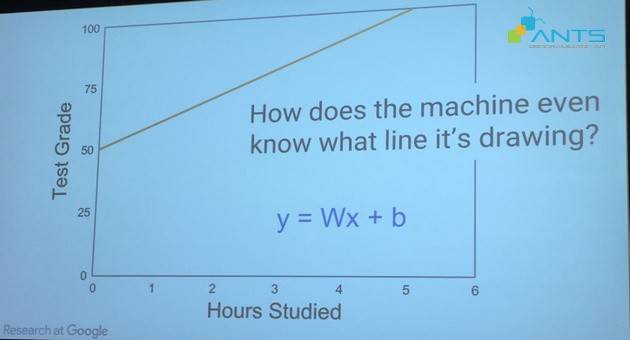
- Mối quan hệ giữa x và y: Ở đây giả định x tác động lên y theo mối quan hệ tuyến tính. Có nghĩa là phương trình biểu diễn mối quan hệ là hàm bậc nhất: y=Wx + b. Hiểu nôm na là: khi ‘thời gian học tập’ tăng lên 1 đơn vị thì ‘kết quả kiểm tra’ sẽ tăng lên (W +b) đơn vị; các thông số W,b này không đổi nên khi biểu diễn trên đồ thị y sẽ là đường thẳng.
- Ngoài ra, dựa trên phỏng đoán chủ quan, giảng viên có thể đưa ra các giả định ban đầu như: W=1, b=5 (y= x + 5).Theo đó thời gian học và điểm số đạt được có thể diễn giải như sau:
0 giờ = 5 điểm
1 giờ = 6 điểm
2 giờ = 7 điểm
3 giờ = 8 điểm
4 giờ = 9 điểm
5 giờ = 10 điểm
Điều này cũng thể hiện rằng giảng viên tin tưởng ‘việc học 5 giờ mỗi ngày sẽ mang lại kết quả kiểm tra tốt nhất (10 điểm) cho sinh viên’.
Như vậy từ những giả thiết ban đầu trên, máy tính sẽ khái quát vấn đề thành phương trình toán học được mô tả như đồ thị bên dưới.
Bước 2 – Cung cấp dữ liệu đầu vào thực tế (Parameter)
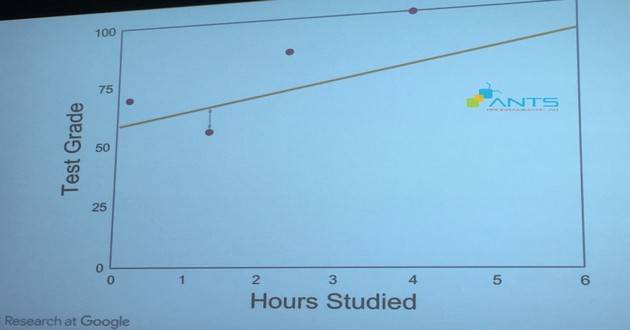
Sau khi mô hình được thiết lập, các thông tin thực tế sẽ được đưa vào. Giáo viên sẽ cung cấp các dữ liệu thực tế về ‘kết quả kiểm tra – x’ và ‘thời gian học tập – y’ được thu thập từ các sinh viên nằm trong mẫu nghiên cứu.
Biểu diễn tập (x,y) của mỗi sinh viên lên đồ thị ở trên và quan sát sơ bộ. Kết quả thực tế không khớp với dự báo: từng điểm chấm (thể hiện cho từng sinh viên với số điểm và thời gian học cụ thể) không nằm ngay trên đồ thị mà phân bổ rải rác bên trên hoặc bên dưới. Điều này chứng tỏ các giả định ban đầu của giảng viên ở bước 1 là không chính xác và cần sự điều chỉnh. Đây chính là lúc quá trình ‘tự học’ của máy tính được kích hoạt.
Bước 3 – Quá trình điều chỉnh tự động (Learner)
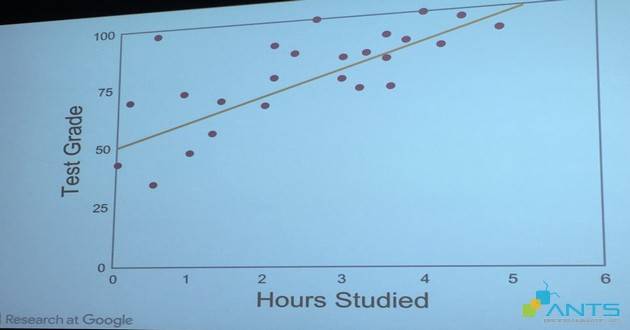
Cơ chế Learner của hệ thống sẽ nhìn vào dữ liệu và các thông số, đánh giá độ chênh lệch giữa thực tế và mô hình, sau đó sử dụng nhiều công thức toán để điều chỉnh các giả định ban đầu, chẳng hạn như W=1, b=4 (y = x + 4). Khi đó:
- 0 giờ = 4 điểm
- 1 giờ = 5 điểm
- 2 giờ = 6 điểm
- 3 giờ = 7 điểm
- 4 giờ = 8 điểm
- 5 giờ = 9 điểm
- 6 giờ = 10 điểm
Với giả định này, máy tính đang điều chỉnh theo hướng cần có nhiều thời gian học hơn (6 giờ) để đạt được điểm số tốt nhất.
Bây giờ chạy lại mô hình với các giả định mới. Số liệu thực tế tiếp tục được so sánh với mô hình được chỉnh sửa. Nếu mô hình thành công thì dữ liệu thực tế phải sát với các số liệu dự báo. Tuy nhiên theo quan sát, dữ liệu thực tế vẫn tiếp tục phân bổ rời rạc thay vì nằm trên hoặc tập trung gần đường mô phỏng. Do đó cơ chế Learner sẽ tiếp tục lặp đi lặp lại các thay đổi cho đến khi mô hình dự báo đạt được độ tin cậy cao nhất – khi đó với mỗi thời gian học nhất định, giảng viên có thể dự đoán gần chính xác điểm số kiểm tra trong thực tế.
Những điểm cần lưu ý
Bên trên chỉ là một phác họa rất đơn giản về qui trình Machine learning để giải bài toán tối ưu hóa, trong đó giá trị của các thông số được chọn sao cho tối ưu một tiêu chuẩn nào đó do người xây dựng mô hình quyết định. Trong thực tế, vấn đề có thể phức tạp hơn rất nhiều:
- Ngoài yếu tố thời gian học tập, còn rất nhiều thứ có thể tác động đến điểm số như khả năng tiếp thu, sức khỏe, điều kiện học tập,… của mỗi sinh viên, và mỗi yếu tố lại tác động không hề giống nhau. Do đó mô hình có thể không đơn giản chỉ là phương trình bậc 1 với một biến số mà có thể phức tạp hơn với nhiều biến hoặc là phương trình đa thức,…
- Mẫu sinh viên được chọn có đủ lớn và có tính đại diện cho tổng thể hay không
- Quan trọng nhất là quan điểm của giảng viên về một mô hình tốt nhất, khả năng dự đoán của mô hình ở mức độ bao nhiêu là vừa, hay về việc xác định một tiêu chuẩn quan tâm nhất và chọn giá trị của tham số sao cho tối ưu tiêu chuẩn này (trong trường hợp này mối quan tâm của giảng viên chính là thời gian học tối đa để tối ưu hóa điểm số).
(Theo www.marketingland.com)






